
Nos últimos tempos um dos temas principais que tenho estudado e pensado sobre é Qualidade para aplicações e sistemas de Machine Learning. Lembro-me de há alguns poucos anos atrás, quando ingressei na área de ML, que não tinha ideia de como medir qualidade. Naquela época, eu estava começando a escrever meus primeiros testes unitários para aplicações WEB e já tinha uma primeira visão sobre o que era qualidade para Software em geral, mas quando contemplado com o conceito de ML eu não tinha ideia do que pensar ou o que procurar.
Nesta pequena séries de artigos, tentarei apresentar um pouco sobre Qualidade para Sistemas/Aplicações de ML, mas mais especificamente sobre testes, monitoramento e algumas dicas sobre situações que você provavelmente encontrará quando lidando com este tema
Iniciaremos, portanto, com uma breve introdução e visão de Sistemas de ML e dos desafios que temos ao lidar com Qualidade.
Sobre Sistemas de ML
O que é um Sistema de ML
Antes de começar, é bom ter um melhor entendimento do que é um sistema de ML, isto nos dará uma melhor compreensão dos desafios que temos para Qualidade. Os sistemas/aplicações de ML são muito diferentes dos tradicionais, principalmente pela adição de eixos extra de complexidade e mudanças (ou um maior número de graus de liberdade); uma visão muito boa disso é dada por Sato, Wider e Windheuser (2019) no artigo CD4ML:

Os autores fornecem não apenas a decomposição do Sistema/Aplicativo, mas também alguns exemplos de mudanças que podem ocorrer nestes novos graus de liberdade:
- Data: esta é a diferença fundamental para Sistemas de ML, principalmente porque o comportamento esperado não é dado pelo código, ou pela aplicação (como em aplicações tradicionais), mas sim pelos dados. Os exemplos disso são possíveis mudanças de schema, volume e diferentes taxas de amostragem ao longo do tempo.
- Model: aqui temos a base para conseguir aprender com os dados, são diferentes técnicas estatísticas e algoritmos que nos permitem fazer predições. Alguns exemplos são algoritmos diferentes (ou modelos), múltiplos experimentos e períodos de treinamento mais longos e com mais recursos.
- Code: a semelhança que temos com as aplicações tradicionais: temos código para configurar modelos, diferentes cenários de serviço (online/batch/streaming), entre outros. Exemplos são mudanças para atender as necessidades de negócio, bug fixes e diferentes configurações.
O ciclo de vida do ML
Se você possui um conhecimento mínimo de ML, provavelmente já está familiarizado com o Ciclo de Vida de Modelos/Machine Learning:
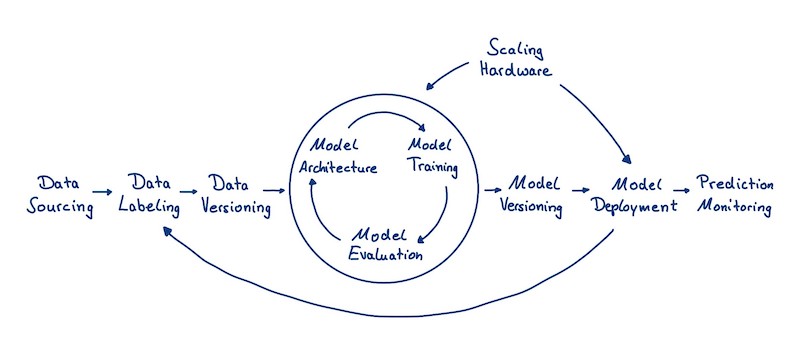
Aqui temos basicamente três fases principais:
- Data Collection: na minha opinião, estas são as etapas mais importantes do ciclo de vida (lembre-se da premissa de ML: Lixo entra, Lixo Sai). Você também pode adicionar etapas de Engenharia de Features no diagrama acima para ter uma visão melhor desta etapa. Geralmente este trabalho está relacionado com o Engenheiro de Dados.
- Model Training: essas etapas estão relacionadas à construção, avaliação e treinamento do modelo. Você provavelmente poderia adicionar a etapa de EDA fora do círculo de otimizações do modelo, para ter uma melhor visão. Aqui temos a função do Cientista de Dados que possui um bom conhecimento dos dados, do negócio e também das técnicas de ML a serem utilizadas.
- Model Deployment: finalmente, temos as etapas relacionadas a implantação do modelo no ambiente de produção, para fazer predições reais. Essas etapas geralmente são executadas pelo Engenheiro de ML, mas você também pode encontrar cenários onde o Engenheiro de Dados também é responsável pela implantação do modelo. Você pode ver que existem algumas situações ou casos em que as predições feitas pelo modelo realimentam os dados de treinamento que serão utilizados para próximas versões ou novos modelos.
Os desafios da Qualidade
Bem, até agora introduzi um pouco dois conceitos gerais que são a composição (ou as partes móveis) e o ciclo de vida de sistemas de ML e, agora, você provavelmente já tem algumas suspeitas referentes aos desafios para a Qualidade neste cenário.
Graus de Liberdade e Equipes Diferentes
Vimos que os sistemas de ML tem três eixos diferentes de complexidade e que estes não evoluem ao mesmo tempo e na mesmo velocidade, não só isso, mas também equipes diferentes podem trabalhar em diferentes etapas do ciclo de vida. Isto significa que ficar de olho nas diferentes mudanças é muito difícil e quase impossível se você tiver muitos modelos em produção e muitas equipes trabalhando em uma mesma organização (diferentes origens, diferentes autores e diferentes ‘donos’); um ambiente muito caótico, de fato.
Para ilustrar, darei dois breves exemplos (que podem ou não estar relacionados a situações reais):
“A organização ABC acaba de implantar seu primeiro modelo de ML para aumentar as vendas, que consiste em uma API. Como eles tinham pouca experiência com o tema, contrataram um engenheiro de dados e um cientista de dados, que juntos trabalham para desenvolver e implantar esse modelo. Eles começam a iterar para novos modelos, mas devido a um bug, eles precisam reverter para a versão anterior. Mal sabiam eles que tinham se esquecido de implementar o controle de versão do modelo e que por causa disso seria uma tarefa muito difícil e trabalhosa para retornar a versão anterior.”
“A organização XYZ está mais madura no tema de Ciência de Dados e tem diferentes modelos de ML em produção, ela também tem: uma equipe dedicada para construir pipelines de dados e serviço de features e outra equipe para construir uma plataforma de ML para treinar modelos e entregar um ambiente de experimentação para Cientistas de Dados. Infelizmente, um dia, após implantar um novo modelo, a equipe de negócios descobre que há algo errado com um determinado sistema de ML e tenta descobrir o que há de errado com ele, mas eles não sabem que há informações espalhadas entre várias aplicações, versões, autores e que a prioridade de cada uma das equipes para resolver o problema é diferente… Como encontrar o culpado e resolver o problema?”
Processo baseado em dados
Outra coisa a se notar é que aplicações baseadas ou orientadas a dados são difíceis. Falaremos sobre testes e qualidade mais pra frente mas, de forma geral, é muito mais fácil definir expectativas (valores ou comportamentos esperados) em aplicações tradicionais porque o comportamento está escrito no código (determinístico), mas e os sistemas de ML onde o comportamento está nos dados?
Você poderia argumentar que esta tarefa é tão fácil quanto separar uma parte do set de testes e definir expectativas sobre essa parte, mas será que podemos ter mesmo certeza de que apenas fazendo isso estamos garantindo qualidade do modelo? Ou talvez algumas instâncias sejam mais difíceis de classificar do que outras? E quanto aos casos extremos ou principais?
Como estamos lidando com um processo orientado por dados, garantir a qualidade de modelo é muito difícil; em um cenário em que também queremos ser capazes de fornecer aplicações éticas (vide LGPD e a temática de Ethical AI) é muito importante garantir expectativas sobre diferentes categorias ou fatias de dados, principalmente porque quando usamos uma única métrica simples não conseguimos capturar todas as diferentes predições e distribuições para subconjuntos diferentes.
Outra coisa muito importante a se ter em mente é que entradas inesperadas serão recebidas pela sua aplicação em algum momento. Pois é, por estarmos lidando com muitas integrações e diferentes aplicações, chegará um momento em que seu modelo receberá um número negativo para idade, ou uma categoria que não existe etc.; se você não for capaz de ‘higienizar’ sua entrada, poderá entrar em uma situação muito ruim, especialmente se o seu modelo retroalimentar sua pipeline de dados para treinamento, e também poderá arriscar tomar decisões erradas (predições).
Dê uma olhada neste exemplo:
“A organização PQR usa ML por um tempo considerável para realizar a prevenção de fraudes. No entanto, ao tentar interpretar um modelo, os cientistas de dados começaram a perceber que uma determinada feature tinha um significado contra-intuitivo (dentro da explicabilidade de modelos) e que também o desempenho do modelo, em diferentes versões, tinha começado degradar desde 9 meses atrás. Até descobrir que uma das features fornecidas para o modelo continha um bug em seu processamento e fornecia valores inesperados para alguns casos que não eram tratados nem observados durante a predição do modelo.”
Muita configuração
Por fim, gostaria de falar um pouco sobre os problemas de configuração. Como vimos acima, no diagrama de Sato, Wider e Windheuser (2019), muitas configurações residem dentro de arquivos que são armazenados no seu VCS (observe que manter a configuração em bancos de dados não é realmente uma boa prática porque introduz erros e torna muito difícil manter o controle). Esses arquivos provavelmente armazenam muitas configurações: sobre seu modelo (para treinamento ou scoring), sobre os dados e também sobre como o processo de treinamento do modelo (hiperparâmetros).
Você pode pensar que este é um assunto muito trivial e inútil, mas ficar de olho na qualidade dos arquivos de configuração é muito importante e pode ser muito complexo dependendo de como o arquivo de configuração é processado/lido. Além disso, uma simples mudança em um parâmetro pode passar despercebida até que você tenha um grande buraco em seu sistema.
Um exemplo para servir de guia:
“Na organização XYZ, um Cientista de Dados desenvolveu uma nova versão para um modelo batch específico. A organização mantém um segundo ambiente para integração e testes completos de ponta a ponta, onde os modelos são implantados antes da produção, mas as especificações dos ambientes são diferentes. Depois de passar em todos os testes, o modelo é implantado e falha em todas as execuções, o Cientista de Dados tenta depurar a execução do modelo usando o ambiente anterior, mas tudo parece funcionar bem. Depois de envolver várias equipes para procurar o problema no ambiente de produção, eles descobrem que um dos parâmetros no arquivo de configuração ainda aponta para o ambiente de backtesting.”
Wrap Up
Neste artigo, tentei apresentar um pouco sobre por que é importante ficar de olho na qualidade dos sistemas de ML e alguns desafios. Vimos alguns pontos sobre diferentes graus de liberdade para os sistemas de ML e também que diferentes equipes e atores são responsáveis por tarefas específicas em seu ciclo de vida.
No próximo artigo, tentaremos examinar os testes e quatro categorias diferentes em que os testes são importantes para sistemas de ML; os exemplos e pontos que levantei aqui são baseados em minha experiência e também em uma lista muito boa de recursos que você encontrará a seguir.
Referências
RUBAN, T. The Deep Learning Toolset — An Overview. 2018. Disponível em: https://medium.com/luminovo/the-deep-learning-toolset-an-overview-b71756016c06
SATO, D. WIDER, A. WINDHEUSER, C. Continuous Delivery for Machine Learning. 2019. Disponível em: https://martinfowler.com/articles/cd4ml.html
BLASZKA, D. Dangerous Feedback Loops in ML. 2019. Disponível em: https://towardsdatascience.com/dangerous-feedback-loops-in-ml-e9394f2e8f43
SCULLEY, D. HOLD, G. GOLOVIN, D. DAVYDOV, E. PHILLIPS, T. Hidden Technical Debt in Machine Learning Systems. 2015. Disponível em: https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
BRECK, E. CAI, S. NIELSEN, E. SALIB, M. SCULLEY, D. The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction. 2017. Disponível em: https://research.google/pubs/pub46555/
